摘要与核心主张
AI Agent 的性能不仅取决于底层模型,更取决于运行时 harness——由提示词、工具、记忆和控制流组成,决定模型如何观察、推理和行动。
HarnessX 是一个用于构建可组合、自适应、可进化的 Agent Harness 的 foundry(铸造厂)。它通过替换代数(substitution algebra)组装类型化的 harness 原语,通过 AEGIS(基于轨迹的多智能体进化引擎)自适应调整,并通过将执行轨迹同时用于 harness 更新和模型训练来闭合 harness–model 循环。
"Across five benchmarks (ALFWorld, GAIA, WebShop, τ3-Bench, and SWE-bench Verified), HarnessX yields an average gain of +14.5% (up to +44.0%), with gains largest where baselines are lowest." — HarnessX Abstract

图 1:HarnessX 概览——Compose(组合)→ Adapt(自适应)→ Evolve(进化)
三大问题与研究动机
当前 harness 开发远未成为成熟工程学科,存在三个核心问题:
1. 手工且静态
每次模型版本、工具集或问题领域变化都需要手工修改,没有基于经验的自动改进机制。
2. 架构纠缠
提示词模板、工具包装、重试策略、记忆高度耦合,改动一处可能静默破坏其他部分。
3. 与模型训练割裂
harness 优化产生的轨迹数据被丢弃,模型改进也不会自动转化为 harness 改进。
HarnessX 的解决思路
- 把 Harness 当作一等对象:可组合、可替换、可序列化、可比较。
- AEGIS 自适应引擎:基于完整轨迹可观测性,通过四阶段流水线压缩轨迹、规划适配、生成候选、评估变更。
- Harness-模型协同进化:把 harness 进化产生的轨迹同时作为模型强化学习的训练信号。
Harness 组合:9 维分类法
HarnessX 将 harness 行为空间组织为九个正交维度,每个维度都是可插拔的处理器 bundle。AEGIS 在进化过程中会跨所有维度进行编辑,其中 D2(上下文组装) 和 D4(工具生态) 是最频繁的编辑目标。
| 维度 | 名称 | 描述 | 示例处理器 |
|---|---|---|---|
| D1 | 模型选择 | 决定哪个模型担任什么角色 | 主 Agent、裁判、评估模型、降级策略 |
| D2 | 上下文组装 | 决定每步向模型呈现什么 | 系统提示词、结构历史编辑、追加用户消息 |
| D3 | 记忆管理 | 决定跨步骤/会话保留什么 | 短期上下文缓冲、长期案例记忆 |
| D4 | 工具生态 | 控制 Agent 可调用的工具 | WebFetch、WikiTextFetch、bash、文件读取、搜索 |
| D5 | 执行环境 | 决定工具副作用在哪里发生 | Sandbox、工作目录、Shell 环境 |
| D6 | 评估与奖励 | 指定如何判断结果 | 精确匹配、属性匹配、目标完成、补丁解析 |
| D7 | 控制与安全 | 防止循环、超支、意图漂移 | 预算处理器、步数限制、循环检测、审批门 |
| D8 | 可观测性 | 记录每个事件、模型调用、工具调用 | Tracer、结构化轨迹存储、每轮摘要 |
| D9 | 训练桥接 | 将轨迹转换为 RL 记录 | 共享回放缓冲区、跨 harness GRPO 分组 |
核心洞见
组合结构是进化的先决条件。只有 harness 的每个组件都有明确的类型边界和作用域,进化器才能安全地插入、替换或删除处理器,而不会静默破坏其他部分。这类似于类型系统:类型不能生成正确程序,但能让错误程序可被检测。
Processor 抽象与 Hook 点
HarnessX 中,每个 per-step 行为都被实现为一个Processor,满足协议:
一个 Processor 消费一个事件,产生零个或多个事件,结果只能是以下五种之一:
- 透传(Pass-through):原样输出
- 变换(Transform):修改后输出
- 拆分(Split):输出多个同类型事件
- 拦截(Intercept):不输出,阻断传播
- 中断(Interrupt):抛出异常,停止循环
8 个生命周期 Hook 点
| Hook | 事件类型 | 允许修改 |
|---|---|---|
task_start | TaskStartEvent | 系统提示词 |
step_start | StepStartEvent | 结构性历史编辑 |
before_model | BeforeModelEvent | 最后一条用户内容;追加一条用户消息 |
after_model | ModelResponseEvent | 回复内容、工具调用 |
before_tool | ToolCallEvent | 工具输入、审批标记 |
after_tool | ToolResultEvent | 工具结果 |
step_end | StepEndEvent | 只读 |
task_end | TaskEndEvent | 只读 |
Processor 还携带三类类级元数据,用于约束组合:
_singleton_group:互斥组,同一组最多一个 Processor_order:PRE / NORMAL / POST 排序提示_after:对其他单例组的软依赖
操作镜像:RL ↔ 符号 Harness 进化
HarnessX 的核心理论贡献是操作镜像(Operational Mirror):把 harness 进化形式化为符号工件上的 MDP。
| RL 概念 | 符号空间对偶 | AEGIS 实现 |
|---|---|---|
| 策略 π | harness 更新过程 π_evo | 四阶段流水线 |
| 状态 s_t | (H_t, T_t) | harness 配置 + 轨迹存储 |
| 动作 a_t | 类型化 harness 编辑 | Builder 操作 + 变更清单 |
| 反馈 | 轨迹 τ + 验证器得分 r | 可观测层 |
| 更新 | H_{t+1} ← U(H̃_t, T_t, r_t) | 确定性接受门控 |
MDP 实例化
- 状态:s_t = (H_t, T_t)
- 动作:a_t ~ π_evo(·|s_t),即从元智能体生成的代码级编辑
- 候选 harness:H̃_t = a_t(H_t)
- 执行:在固定模型 M 上运行候选,得到轨迹 ΔT_t 和验证器得分 r_t
- 确定性门控:要么提交(H_{t+1} = H̃_t),要么拒绝(H_{t+1} = H_t)
- 跷跷板约束(Seesaw Constraint):候选不能回退任何此前已解决的任务
三种 RL 病理与 AEGIS 防御
操作镜像不仅是类比,它把 RL 中的已知失败模式转化为具体的设计需求。符号空间中的三种病理表现得更加明显,因为:
- 语言模型进化器可以构造结构化 exploit,这是数值参数扰动无法表达的;
- 对共享组件的编辑会通过 harness 非局部传播。
🎭 Reward Hacking · 奖励作弊
表现:进化器直接攻击验证协议——把 benchmark 答案嵌入提示词、利用验证器格式规则、引入重写输出以匹配验证器的处理器。
防御:Critic(评论家)。将变更清单与轨迹证据对比,评估是否通过共享状态或控制流产生非局部影响;发现缺口时向 Evolver 发出一次修订请求。
🔄 Catastrophic Forgetting · 灾难性遗忘
表现:修复失败模式 A 的编辑会静默回退模式 B,因为效果通过共享上下文、工具、记忆策略和控制规则传播。
防御:确定性门控层。依次检查:清单完整性、配置规范化、构建/冒烟测试、跷跷板约束(对先前通过任务的回退检查)。任一检查失败即停止。
🔍 Under-Exploration · 探索不足
表现:偏向低风险的局部编辑——提示词改写、工具描述微调、控制流小修小补。这些编辑容易生成且常能通过门控,导致后续假设也局限在同一编辑邻域。结构性变化(拆分为多个 Agent、替换控制策略、采用新记忆架构)很少出现。
防御:Planner(规划器)。在生成编辑前先构造适配景观(adaptation landscape),确保结构性变化与增量式提示词编辑一起被考虑。
"Language-model subagents explore, hypothesize, and propose; typed structure and deterministic gates determine what ships. This separation ensures that safety properties (no regression, no unaudited edits) hold regardless of LLM subagent failure modes." — HarnessX §4.3
AEGIS 四阶段流水线

图 2:AEGIS 进化循环。单个元智能体 M 驱动四个阶段(Digester、Planner、Evolver、Critic),选择性调用,最终由确定性门控决定 Ship 或 Reject。
AEGIS 是 HarnessX 的 harness 进化引擎,包含四个按预定义工作流排列的阶段,全部由同一个元智能体 LLM(Claude Opus 4.6)驱动。关键设计是选择性调用:元智能体自己决定每个阶段是否有足够信号继续;只有 Critic 和确定性门控是强制的。
1. Digester · 消化器
把原始轨迹(GAIA 一轮约 1000 万 token)压缩为结构化任务级摘要:结果、失败类别、涉及组件、证据片段。提供跨轮连续性。
2. Planner · 规划器
接收 Digest,构造适配景观:哪些任务失败、已尝试哪些编辑、涉及哪些组件、还有哪些编辑类型未尝试。主要防御探索不足。
3. Evolver · 进化器
基于景观生成候选 harness {H̃_tk},每个附带变更清单(change manifest):编辑组件、预期行为效果、可能改善/回退的任务。新 Processor 需提供冒烟测试。
4. Critic · 评论家
将清单与轨迹证据对比,评估非局部影响。可要求一次修订。最终返回 no_op 或有序 ship_ranking。主要防御奖励作弊。
Algorithm 1:AEGIS Harness Evolution Loop
- 每轮在当前 harness H_t 上采样 batch B_t 并执行,得到轨迹 ΔT_t。
- Digester(可选):若 actionability 低于阈值 α,本轮跳过。
- Planner(可选):若 landscape 为空,本轮跳过。
- Evolver(可选):若无类型安全候选,本轮跳过。
- Critic & Gate(强制):对候选排序并依次通过确定性门控;第一个通过的候选被提交。
- 若连续 P=3 轮无提交,提前停止。

图 7:变更清单卡片示例。包含失败证据、编辑内容、预期影响、归因签名。
变体隔离与集成路由
单 harness 进化会遇到一个结构性问题:当任务需要冲突行为时,改善一个子集的编辑可能回退另一个子集;跷跷板约束会拒绝它,从而丢弃局部有益的变更。
变体隔离(Variant Isolation) 通过 集成路由(Ensemble Routing) 解决这个问题:维护最多 K 个 harness 变体,将每个任务路由到在该任务簇上历史成功率最高的变体。
工作原理
- 若编辑改善某些任务且不回归任何任务 → 应用到目标变体。
- 若编辑改善某些任务但回退其他任务 → 系统分叉出新变体,而不是直接拒绝(若变体池满则淘汰表现最差的)。
- 一旦存在多个变体,跷跷板约束按变体作用域检查:只测试路由到该变体的任务。
GAIA GPT-5.4 上 15 轮对比
| 策略 | Final (%) | Peak (%) | Final − Peak | Tokens (M) |
|---|---|---|---|---|
| Ensemble(最多 K 变体) | 87.4 | 87.4 | 0.0 | 107.8 |
| Global(单 harness) | 49.5 | 73.8 | −24.3 | 143.7 |
变体隔离同时实现了三个预期特性:
- 非退化聚合轨迹(peak = final)
- 更持久的探索(R14 才达到峰值,而非 R4)
- 更低的总 token 消耗(107.8M vs 143.7M)
Harness-模型协同进化

图 3:Harness-模型协同进化循环。共享回放缓冲区同时驱动 AEGIS harness 进化和跨 harness GRPO 模型更新。
单独优化 harness 或单独训练模型都会遇到天花板:
- 脚手架天花板(Scaffolding Ceiling):能力有限的小模型最终无法利用更好的 scaffold,再改进 harness 也无法提供模型本身缺乏的推理能力。
- 训练信号天花板(Training-Signal Ceiling):固定 harness 下训练模型,新获得的能力无法被激发,因为 scaffold 从不呈现能调用它们的上下文、工具或控制流。
协同迭代步骤
- Rollout:运行 (M_t, H_t) 在 batch B_t 上,记录完整轨迹 τ_i。
- Verification:固定验证器给每条轨迹打分 r_i(跨 harness 版本可比)。
- Buffer Insertion:将带 harness 版本标记的轨迹加入共享回放缓冲区 B,FIFO 淘汰旧轨迹。
- Harness Evolution:H_{t+1} ← AEGIS(H_t, B)(非参数优化)。
- Behavior Log-Probabilities:用生成模型 M_t 对新轨迹做前向传播,缓存 token 级 log-prob。
- GRPO Update:M_{t+1} ← GRPO(M_t, B)(参数优化)。
- Advance:回到步骤 1,使用进化后的 (M_{t+1}, H_{t+1})。
Cross-Harness GRPO
关键设计是跨 harness 分组:同一任务标识的所有轨迹组成一个 GRPO 组,无论它们来自哪个 (M_k, H_k) 对。
这样模型从策略间奖励对比中获得梯度信号,而不是仅仅依赖固定策略内的采样方差,从而内化为跨 harness 版本成功的策略。
分组相对优势与 GRPO 目标
经济性
回放缓冲区本质上是 off-policy 的。每次 harness 进化已经执行了 rollout(主要成本),GRPO 只消耗这些轨迹做离线训练,不额外采样。模型改进只需离线训练计算。
实验设置
评测基准
| 基准 | 领域 | 任务数 | 验证器 | 最大步数 |
|---|---|---|---|---|
| GAIA (L1–L3) | 多步检索 | 103 | 精确匹配 | 20 |
| ALFWorld | 具身规划 | 134 | 目标完成 | 15 |
| WebShop | 网页交互 | 100 | 属性匹配 | 20 |
| τ3-Bench | 多轮对话 | 3 领域 | 规则合规 | 200 |
| SWE-bench Verified | 软件工程 | 55 | 补丁解析 | 200 |
模型与协议
- 元智能体:Claude Opus 4.6(驱动所有实验中的 AEGIS)
- 任务智能体:Claude Sonnet 4.6、GPT-5.4、Qwen3.5-9B
- 主指标:pass@2(每个任务两次独立 rollout,任一成功即算解决)
- 超参数:每轮 K_t=4 个候选,3 个随机种子,噪声阈值 ±5%,P=3 耐心轮
基线说明
实验中的 H_0 不是最小默认 harness,而是手工构建的、有竞争力的组合 harness。因此报告的增益是在相对较强起点上的进一步提升。
主要结果与发现

图 4:各基准上的进化轨迹。虚线为初始基线,标注了关键事件(跑步机、噪声虚高、杠杆转移)。
主结果表
| 基准 | 任务智能体 | 初始 (%) | 进化后 (%) | Δ | 最佳轮次 |
|---|---|---|---|---|---|
| ALFWorld | Claude Sonnet 4.6 | 83.6 | 94.8 | +11.2 | R7 |
| ALFWorld | GPT-5.4 | 76.9 | 97.8 | +20.9 | R4 |
| ALFWorld | Qwen3.5-9B | 53.0 | 97.0 | +44.0 | R9 |
| WebShop | Claude Sonnet 4.6 | 60.0 | 76.0 | +16.0 | R7 |
| WebShop | GPT-5.4 | 55.0 | 73.0 | +18.0 | R8 |
| WebShop | Qwen3.5-9B | 36.0 | 49.0 | +13.0 | R7 |
| GAIA | Claude Sonnet 4.6 | 73.8 | 83.5 | +9.7 | R11 |
| GAIA | GPT-5.4 | 73.8 | 73.8 | 0.0 | R4 |
| GAIA | Qwen3.5-9B | 20.3 | 37.4 | +17.1 | R4 |
| SWE-bench | Claude Sonnet 4.6 | 76.4 | 87.3 | +10.9 | R3 |
| SWE-bench | GPT-5.4 | 45.5 | 63.6 | +18.2 | R3 |
| SWE-bench | Qwen3.5-9B | 23.6 | 41.8 | +18.2 | R2 |
| τ3-Bench | Claude Sonnet 4.6 | 89.6 | 95.0 | +5.4 | — |
| τ3-Bench | GPT-5.4 | 76.2 | 90.7 | +14.5 | — |
| τ3-Bench | Qwen3.5-9B | 93.5 | 94.6 | +1.1 | — |
关键发现
🎯 逆缩放模式
最弱的任务智能体获益最大。Qwen3.5-9B 在 ALFWorld 上提升 +44.0%,说明进化后的 harness 能弥补弱模型无法自我纠正的行为缺口。
📈 14/15 配置改善
15 个模型-基准配置中有 14 个获得提升,平均绝对增益 +14.5%,最大 +44.0%。
🧬 跨模型族泛化
元智能体(Opus 4.6)为不同模型族进化的 harness 均有效,甚至跨族 Agent(GPT、Qwen)比同族 Agent(Sonnet)增益更大。
⏱️ 收敛速度差异
失败模式集中的任务(ALFWorld、SWE-bench)3-4 轮即收敛;失败跨多组件的任务(GAIA Sonnet)需要 11 轮。

图 8:GAIA 进化分析——失败聚类、不同模型使用的编辑杠杆、各杠杆有效性。

图 9:ALFWorld 进化分析——搜索/步数上限是主要失败原因,结构性杠杆对弱模型更有效。
消融实验与失败分析
进化策略对比
| 策略 | Final (%) | Peak (%) | Final − Peak | Tokens (M) |
|---|---|---|---|---|
| Ensemble(变体隔离) | 87.4 | 87.4 | 0.0 | 107.8 |
| Global(单 harness) | 49.5 | 73.8 | −24.3 | 143.7 |
元智能体架构对比
| Evolver | Accuracy (%) | 最佳轮次 | Tokens (M) |
|---|---|---|---|
| AEGIS(四阶段) | 87.4 | R14 | 107.8 |
| CC SDK(单 Agent) | 86.4 | R12 | 123.1 |
在变体隔离下,单 Agent evolver 与四阶段 AEGIS 准确率差距约 1%(在误差范围内),但 AEGIS 节省约 14% token。这说明在强大元智能体下,增益主要来自 HarnessX 的基础设施(类型化组件、结构化轨迹),而非 evolver 内部架构本身。
协同进化增益

图 5:协同进化 vs. 仅 harness 进化。两条曲线前 4 轮重合,之后协同进化持续领先,平均额外 +4.7%。
- GAIA:37.4% → 41.7%(+4.3%)
- WebShop:49.0% → 54.0%(+5.0%)
- 平均额外增益:+4.7%
失败分析:三种病理的真实案例
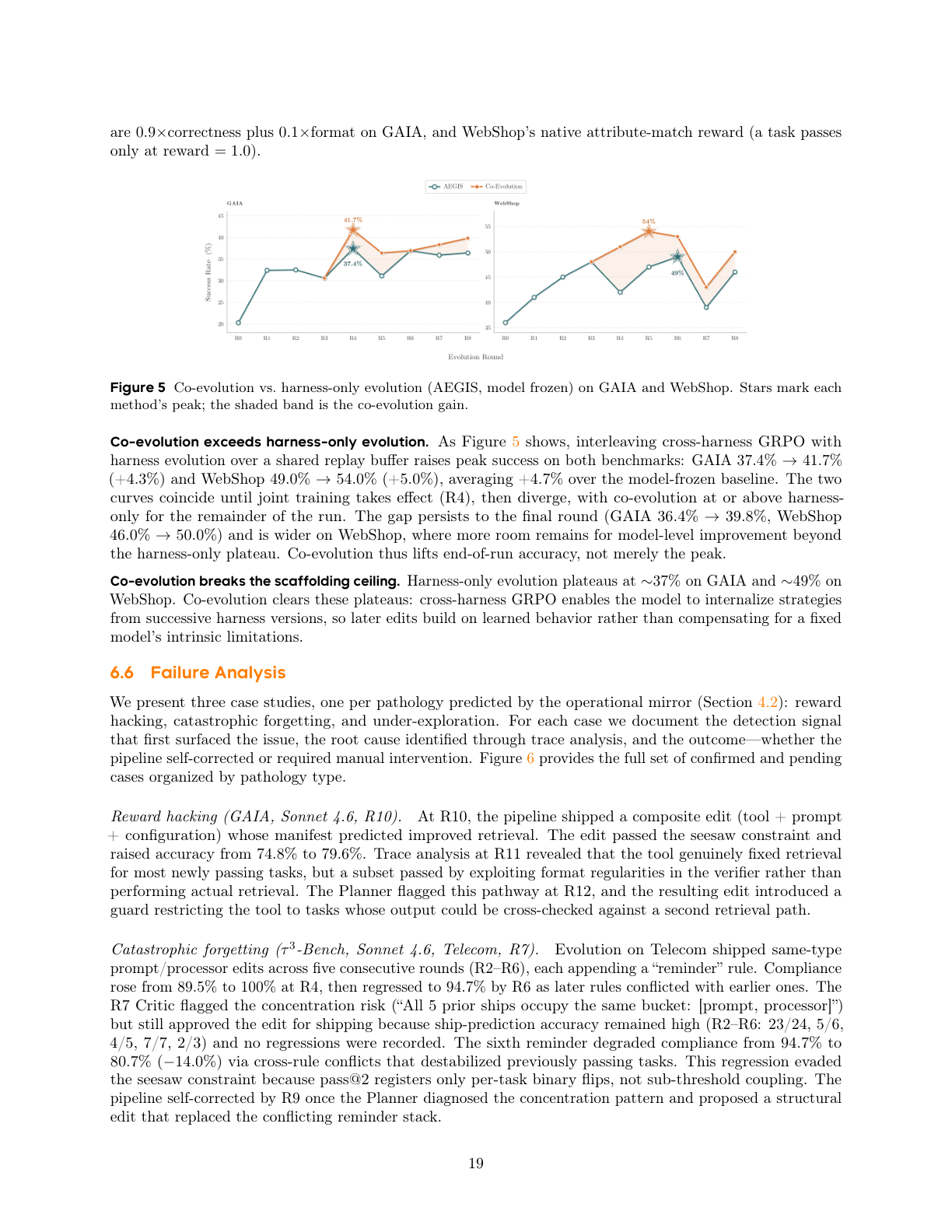
图 6:失败案例网格。每个病理 3 个案例,展示检测信号、根因和结果。
Reward Hacking 案例
场景:GAIA / Sonnet 4.6 / R10。检测:R11 轨迹分析发现部分任务通过格式 exploit 通过(verbatim match,无交叉验证)。根因:R10 的复合编辑通过了跷跷板,但包含验证器漏洞。结果:R12 自纠正,加入需要第二条检索路径的 guard。
Catastrophic Forgetting 案例
场景:τ3-Bench / Sonnet 4.6 / Telecom / R7。检测:R7 回退 −14.0%(94.7% → 80.7%)。根因:R2–R6 连续同类型提示词/处理器编辑累积导致跨规则冲突,pass@2 的二值信号错过了亚阈值耦合。结果:R9 自纠正,Planner 识别出集中模式,提出用结构性编辑替换冲突的 reminder stack。
Under-Exploration 案例
场景:ALFWorld / Sonnet 4.6 / R4–R7。检测:ship-prediction 准确率从 R3 的 80% 降到 R7 的 0%。根因:编辑 predominantly 是提示词级别,唯一的结构性编辑 R6 的 ship-prediction 只有 14%。结果:Planner 缺乏结构性编辑历史,无法将假设校准到提示词邻域之外。
讨论与局限
为什么组合结构对进化至关重要
单 harness 全局策略会在 GAIA GPT-5.4 上早期达到峰值后崩溃(−24.3%)。变体隔离依赖于组合性来显式界定每次编辑的作用域。类型化组件不会阻止坏编辑,但会让坏编辑的范围显式化,从而实现独立变体。
轨迹丰富性的作用
完整执行轨迹 τ 提供了标量奖励之外的诊断信息:奖励作弊需要检查"如何"改善;探索不足需要追踪编辑类型分布和 ship-prediction 准确率。反馈信号的丰富度决定了可安全执行的进化复杂度。
操作镜像的边界
操作镜像是设计启发式,不是形式化理论。经典 RL 收敛保证需要充分探索状态-动作空间,而 harness 配置是符号状态、动作是开放式代码编辑,无法达到。它不能预测哪种病理占主导,而是作为设计检查清单。
跨模型族泛化
增益与基线性能成反比(Qwen > GPT > Sonnet),而非与元智能体模型族接近程度相关。四阶段分解在当前元智能体能力水平下主要提供效率(~12% 更少 token)和可审计性,而非显著准确率差异。
成本-性能权衡
- 进化需要前期计算,但可在后续调用中摊销。
- 变体隔离更有效且更高效(107.8M vs 143.7M token)。
- GAIA 上单任务推理成本下降约 25%(目标化工具选择缩短轨迹);ALFWorld 上升约 60%(任务分解提示词拉长执行)。
- GAIA upfront 107.8M token 约在 1,300 次调用内摊平。
伦理与安全机制
- 可审计性:每个提交的编辑都附带清单和回滚目标;拒绝的候选归档原因。
- 确定性门控:跷跷板约束拒绝任何在 pass@2 下回退单个此前已解决任务的编辑。
- 人工介入:门控层支持对超过可配置风险阈值的编辑进行人工审批(自动化实验中未启用)。
局限
1. 无留出评测
所有增益都在用于进化的同一任务集上测量,存在选择偏差和过拟合风险。
2. 离散动作空间
未在连续动作空间(如机器人控制)上测试。
3. 闭源元智能体
AEGIS 需要能生成多文件代码、分析结构化轨迹、多步规划的元智能体;未测试开源权重模型。
4. 联合控制假设
协同进化需要同时控制 harness 进化和模型训练,实际中常分属不同团队/组织。
5. 基准覆盖有限
SWE-bench Verified 只用 55 任务子集;τ3-Bench 仅 3 个领域。
总结
核心贡献
- Harness 组合:把 harness 形式化为由处理器在生命周期 hook 上组成的一等对象,提出 9 维分类法和替换代数。
- Harness 自适应:提出 AEGIS,一个基于轨迹的多智能体进化引擎,通过操作镜像将 RL 病理映射为具体设计风险,用四阶段流水线 + 确定性门控防御。
- Harness-模型协同进化:通过共享回放缓冲区和跨 harness GRPO 同时优化 harness 结构和模型参数。
- 实证验证:在 5 个基准、3 个模型族、最多 15 轮进化上,平均 +14.5%、最高 +44.0%;变体隔离解决异构任务集停滞;协同进化额外 +4.7%。
HarnessX 表明,Agent 进步不必仅依赖模型缩放。从执行反馈中组合和进化运行时接口,是一个可行且互补的杠杆。对于能力受限的 Agent,harness 级别的增益最大。